Kita sering bicara mengenai model machine learning, mulai dari regresi linear, k-nearest neighbours, pohon keputusan, naive bayes, hingga sang hippest kid on the block, deep learning. Kita tahu apa itu model klasifikasi, apa itu model regresi, apa itu model clustering, tetapi mendefinisikan model machine learning itu sendiri ternyata lebih sulit. Mencari definisinya dari Google dan Wikipedia pun tidak membuahkan jawaban yang memuaskan (meski terdapat diskusi yang cukup menarik di sini).

Jika disebut model machine learning, scikit-learn yang masih bertengger at the top of my head. Gambar dari http://scikit-learn.org
Model
Apakah sebenarnya yang dimaksud dengan model machine learning? Lalu, di dalam machine learning, apakah model sama dengan algoritma?
For practical purposes, I like to think machine learning models as programs.
Lebih tepatnya, model machine learning merupakan suatu kelas dengan satu metode, yaitu map(). Metode atau fungsi tersebut memetakan input menjadi output, dari satu domain ke domain lainnya. Contohnya, model regresi memetakan input dalam RD menjadi output dalam R, dan model klasifikasi memetakan input dalam RD menjadi output dalam himpunan berhingga.

Model machine learning. Hanya perlu satu fungsi map() untuk memetakan input menjadi output
Kalau hanya berupa program, bisa dong model machine learning sesederhana ini?
class SeeminglyStupidModel:
def map(self, input):
return 1
Yup, sangat bisa. Meski mengabaikan input, program (model) inilah yang paling tepat jika output dalam data yang kita miliki semuanya bernilai 1.
Parameter
Tetapi tentu model di atas tidak akan banyak berguna untuk memecahkan real world problems. Untungnya, para pendahulu kita telah berjerih payah menciptakan model-model yang tidak hanya lebih menarik dari segi program namun juga jauh lebih bermanfaat. Misalnya model regresi linear yang dikembangkan Adrien-Marie Legendre pada abad ke-19:
class LinearRegression:
…
def map(self, input):
return self.W * input + self.b
Model ini memetakan input menjadi output dengan suatu transformasi linear (perkalian input dengan konstanta lalu ditambah konstanta lainnya).
Perhatikan bahwa di dalam model tersebut terdapat variabel W dan b yang tidak dimiliki SeeminglyStupidModel dan entah dari mana datangnya. Variabel-variabel ajaib ini disebut parameter, bobot (weights), atau koefisien (coefficients).
Adanya parameter membuat LinearRegression jauh lebih fleksibel dibanding SeeminglyStupidModel, dalam artian mampu memetakan lebih banyak data dari domain input ke domain output dengan tepat. Namun nilai W dan b yang datang dari langit (i.e. acak) sangat mungkin tidak sesuai dengan data latih yang kita miliki. Lantas bagaimana cara memperoleh nilai yang tepat untuk kedua parameter tersebut?
Optimisasi
Proses menentukan nilai parameter inilah yang dikenal sebagai optimisasi di dalam machine learning. Selama optimisasi, nilai parameter model akan disesuaikan berdasarkan data latih (training data) yang kita berikan. Harapannya, model yang dihasilkan cukup akurat untuk memetakan input menjadi output sesuai pola yang ditemukan di dalam data latih.
Optimisasi pun dapat dipandang sebagai sebuah program yang menerima masukan berupa sekumpulan data dan menghasilkan luaran berupa model. Sebagai contoh, untuk optimisasi iteratif seperti gradient descent, programnya kurang lebih seperti berikut:
def some_optimization_function(model, data):
do:
outputs = model(data) # Transformasi input menjadi output
obj = objective_fn(data, outputs) # Hitung akurasi atau kesesuaian output dengan data
update_parameters(model, obj, data, outputs) # Optimisasi model, mencari nilai parameter yang lebih tepat
while not is_optimization_done(…)
return model
Pilihan teknik optimisasi sangat bervariasi. Ada yang khusus diterapkan untuk jenis model tertentu (misalnya solusi tertutup regresi linear), dan ada yang berlaku umum (misalnya gradient descent). Ada yang langsung memakai semua data latih (full batch gradient descent), dan ada yang memakai data latih secara inkremental (stochastic gradient descent). Ada yang berdasarkan maximum likelihood, dan ada yang berdasarkan teorema Bayes. Jenis model tertentu seperti k-nearest neighbours bahkan sebenarnya tidak memerlukan optimisasi apa-apa karena ia hanya menyimpan semua data latih untuk dipakai memetakan input baru.
Hyperparameter
Sekarang kita sudah tahu apa itu model machine learning dan bagaimana cara memperoleh model (parameter) yang akurat. Apakah machine learning cukup sampai di sini saja?
Ternyata tidak. Ada lagi komponen model yang dinamakan hyperparameter. Wah tadi sudah ada parameter, apa lagi itu hyperparameter?
Layaknya parameter, hyperparameter adalah variabel yang memengaruhi output model. Bedanya, nilai hyperparameter tidak diubah selama model dioptimisasi. Dengan kata lain, nilai hyperparameter tidak bergantung pada data dan selalu kita ambil as given saat pendefinisian model. Dua model dengan jenis yang sama namun hyperparameter berbeda bisa memiliki bentuk (i.e. memberikan output) yang berbeda pula.
Mari lihat contoh supaya lebih jelas bagaimana hyperparameter memengaruhi output model. Untuk model k-nearest neighbours kita mengenal hyperparameter k = banyaknya tetangga data yang diperhatikan dalam memetakan input.
class KNN:
def __init__(self, k):
# Inisialisasi hyperparameter. Perhatikan bahwa hyperparameter sudah given saat model didefinisikan
self.k = k
# Inisialisasi parameter
self.training_data = None
def map(self, input):
neighbours = find_neighbours(input, self.training_data, k=self.k)
return count([x.output for x in neighbours]).argmax()
k-nn dengan k = 1 dan k = 5, misalnya, sangat mungkin memberikan output yang berbeda meski diberikan input yang sama.
Selain memengaruhi output, hyperparameter juga dapat menentukan bagaimana parameter diinisialisasi dan diperbarui selama optimisasi (namanya juga hyper). Contohnya adalah hyperparameter jumlah lapisan dan jumlah unit per lapisan dalam feed-forward neural network.
class FeedForwardNet:
def __init__(self, num_units_per_layer, layer_activation_fns):
# Inisialisasi hyperparameter
self.num_units_per_layer = num_units_per_layer
self.num_layers = len(self.num_units_per_layer)
self.layer_activation_fns = layer_activation_fns
# Inisialisasi parameter (layers). Perhatikan bahwa inisialisasi ini dipengaruhi oleh nilai hyperparameter
self.layers = [ ]
for i in range(self.num_layers):
layer = {}
layer[‘W’] = initialize_W(self.num_units_per_layer[i])
layer[‘b’] = initialize_b(self.num_units_per_layer[i])
layer['activation_fn'] = self.layer_activation_fns[i]
self.layers.append(layer)
def map(self, input):
h = input
for layer in self.layers:
z = layer[‘W’] * h + layer[‘b’]
h = layer['activation_fn'](z)
return h
Jumlah lapisan menjadi hyperparameter karena tidak berubah selama optimisasi model, begitu pula fungsi aktivasi dan jumlah elemen dalam masing-masing layer[‘W’] dan layer[‘b’]. Namun, nilai setiap elemen layer[‘W’] dan layer[‘b’] merupakan parameter yang terus diperbaiki selama optimisasi.
Bisa dibayangkan, baik pada contoh k-nn maupun feed-forward net di atas, nilai hyperparameter akan sangat memengaruhi output model. Pertanyaan selanjutnya adalah bagaimana menentukan nilai hyperparameter dengan tepat? Mungkin sudah tidak asing lagi, yaitu melalui proses hyperparameter tuning. Singkatnya, kita menentukan beberapa set nilai hyperparameter, mengoptimisasi satu model untuk masing-masing set, dan memilih model yang menghasilkan output paling akurat.
Jika kita menentukan 3 set hyperparameter, pada akhir hyperparameter tuning kita akan memiliki 3 nilai akurasi (1 untuk masing-masing set). Kita ambil hyperparameter atau model dengan akurasi tertinggi dari ketiga pilihan yang ada.
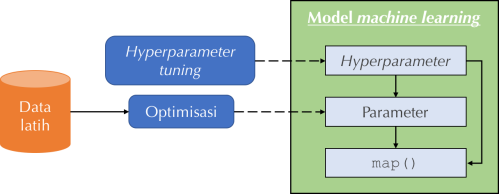
Skema optimisasi dan hyperparameter tuning. Parameter dan hyperparameter pada akhirnya sama-sama memengaruhi metode map()
Selengkapnya mengenai optimisasi dan hyperparameter tuning dapat dibaca di blog ini.
Rangkuman
Kita telah mempelajari beberapa konsep yang menggambarkan model machine learning, antara lain:
- Model machine learning dapat dianggap sebagai kelas program yang memiliki metode
map()untuk memetakan input menjadi output - Model machine learning juga memiliki parameter dan hyperparameter yang nilainya memengaruhi
map()(dan output) - Nilai parameter dioptimisasi berdasarkan data latih agar diperoleh pemetaan input-output yang sesuai dengan data
- Nilai hyperparameter tidak bergantung pada data dan konstan selama model dioptimisasi. Nilai yang paling tepat untuk hyperparameter dipilih melalui hyperparameter tuning
Terakhir, menjawab pertanyaan di awal pos: apakah model machine learning sama dengan algoritma? Istilah model dan algoritma memang sudah sangat interchangeable dalam diskusi machine learning, walaupun keduanya mengacu pada sesuatu yang berbeda. Model adalah pemetaan input menjadi output (i.e. program, seperti yang dijelaskan di atas), sedangkan algoritma adalah metode pembelajaran (learning) untuk mendapatkan model itu sendiri. Dalam konteks ini algoritma lebih sepadan dengan optimisasi ketimbang dengan model.
Apakah Anda setuju dengan definisi yang saya berikan?

Awesome blog post!
Keep it going!
SukaSuka
Hi ikibozu, terima kasih atas dukungannya 🙂
SukaSuka
makasih bang, sangat bermanfaat
SukaSuka