Ada kalanya Anda butuh metode untuk dapat menemukan kelompok atau subpopulasi dalam data. Jadi, tidak seperti banyak algoritma yang kita telah bahas dalam blog ini, seperti regresi linear, k-NN, atau neural networks, Anda tidak memerlukan label dari tiap objek untuk dibandingkan. Dengan kata lain, Anda hanya perlu mencari objek yang serupa dalam data Anda. Apa yang menjadi kesamaan objek-objek tersebut? Untuk mengerjakan hal ini, kita dapat menggunakan ide yang telah dipelajari dalam materi k-Nearest Neighbours, yaitu konsep kedekatan antarobjek.
Sebagai contoh, Anda ingin mengelompokkan mahasiswa teknik informatika di suatu universitas. Maka, Anda dapat mengelompokkannya berdasarkan kesamaan kelas yang diambil. Di sisi lain, Anda bisa juga mengelompokkannya berdasarkan usia atau IPK. Ketika Anda telah menemukan kelompok-kelompok tersebut, maka ada kemungkinan untuk menemukan pencilan dalam data yang Anda punya. Bisa jadi, pencilan ini adalah mahasiswa yang usianya masih sangat muda karena kelas akselarasi. Namun, bisa juga dia menjadi pencilan karena IPK-nya jauh di atas teman-teman yang lainnya. Jadi, perlu diingat bahwa dalam proses pengelompokan atau clustering tersebut, Anda boleh jadi menggunakan lebih dari satu dimensi.
Contoh yang lain: Jika dalam bidang Cartesian Anda mendapatkan data seperti pada gambar di bawah ini, menurut Anda, berapa subpopulasi yang Anda bisa temukan?

Sebagian besar orang mungkin akan melihat ada tiga atau empat subpopulasi dalam data tersebut. Anda mungkin tidak begitu yakin antara dua pilihan tersebut. Lalu, apa yang harus dilakukan?
k-Means
Algoritma k-Means adalah salah satu cara untuk melakukan clustering dengan memanfaatkan konsep centroid atau titik tengah. Centroid adalah titik pusat yang merupakan rata-rata dari nilai objek dalam tiap dimensi. Dalam algoritma k-Means, ada sejumlah 

k-Means dengan 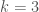
Nilai centroid diinisialisasi secara acak dalam tiap dimensi. Lalu, nilai centroid ini dimutakhirkan sesuai dengan objek yang paling dekat dengan centroid tersebut secara iteratif. Kumpulan objek terdekat dengan centroid tersebutlah yang kemudian dianggap sebagai satu cluster. Untuk melakukan hal ini, k-Means memanfaatkan algoritma umum yang dikenal juga sebagai Expectation-Maximization (EM). Secara umum, algoritma k-Means dapat dituliskan sebagai berikut.
Inisialisasi k centroid secara acak while belum konvergen do tahap-E: Masukkan tiap titik/objek ke centroid terdekat tahap-M: Ubah nilai centroid menjadi rata-rata dari tiap titik/objek
Secara matematis, tahap-E dapat dirumuskan sebagai
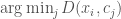
dan tahap-M dirumuskan sebagai

dengan nilai 





Menentukan Nilai
Sayangnya, algoritma seperti k-Means tidak dapat menemukan nilai
Salah satu cara untuk menentukan 
Untuk menghasilkan scree plot, kita perlu menghitung nilai total jarak antara tiap titik dengan centroid terdekatnya. Secara matematis, nilai yang juga dikenal sebagai inertia ini didefinisikan sebagai
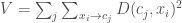
sehingga menghasilkan plot seperti pada gambar di bawah. Nilai 


Mengevaluasi Clustering
Ada dua cara untuk mengevaluasi algoritma clustering secara umum: ekstrinsik dan intrinsik. Meski metode clustering tidak punya metric yang pasti, tetapi ada beberapa pendekatan yang dapat dilakukan untuk mengukur seberapa baik pembagian cluster yang telah kita lakukan. Evaluasi ekstrinsik dilakukan dengan menggunakan clusters yang telah dihasilkan untuk tugas yang lain, misalnya untuk menemukan pencilan atau menggunakannya sebagai atribut untuk melakukan klasifikasi.
Di sisi lain, evaluasi intrinsik salah satunya dapat dilakukan dengan menggunakan kelas aslinya sebagai referensi. Misalkan kita punya clusters 
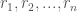
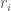


Untuk memperjelas, dalam kasus clustering untuk menentukan kelompok karakter dalam sandiwara Julius Caesar karya William Shakespeare, kita dapat secara greedy menentukan grup 
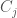

Untuk menghitung akurasinya, kita hanya perlu menghitung nilai yang dicetak biru sebagai jumlah yang benar, lalu bagi nilainya dengan jumlah seluruh karakter yang ada dalam data. Nilai yang dicetak biru merupakan irisan terbesar yang dicari untuk setiap
Contoh Implementasi dan Aplikasi
Penggunaan k-Means dengan Python dapat dilakukan dengan cukup mudah berkat bantuan pustaka scikit-learn. Untuk mengevaluasinya dengan menggambarkan scree plot pun hanya perlu beberapa baris kode saja. Anda dapat melihat contoh kode di bawah ini.
| import matplotlib.pyplot as plt | |
| from sklearn.datasets.samples_generator import make_blobs | |
| from sklearn.cluster import KMeans | |
| # Anda dapat mengganti nilai X dan y sesuai dengan kebutuhan Anda | |
| X, y = make_blobs(n_samples=300, centers=4, | |
| cluster_std=1.2, random_state=3) | |
| inertia = [] | |
| for k in range(1,11): | |
| kmeans = KMeans(n_clusters=k) | |
| kmeans.fit(X) | |
| inertia.append(kmeans.inertia_) | |
| plt.plot(range(1,11), inertia, c='orange', zorder=1) | |
| plt.scatter(range(1,11), inertia, zorder=2) | |
| plt.xlabel('$k$') | |
| plt.ylabel('jarak agregat') | |
| plt.savefig('scree.png') |
Secara umum, algoritma ini dapat digunakan untuk mencari subpopulasi dalam data. Kapan hal tersebut akan dilakukan? Salah satu contoh yang paling sering dikaitkan dengan metode ini adalah untuk customer segmentation. Anda dapat mengelompokkan pengguna suatu produk atau layanan dengan menggunakan berbagai atribut yang melekat pada pengguna tersebut maupun dari pola belanjanya.
Algoritma k-Means juga dapat digunakan untuk melakukan kompresi gambar. Jika kita melihat warna pixels dalam kanal RGB, maka kita dapat menerapkan clustering untuk kemudian menggunakan nilai centroid-nya sebagai representasi pixels dengan warna yang berdekatan. Dalam contoh yang kita gunakan, representasi tersebut kemudian dapat digunakan untuk mengompresi gambar dengan faktor hingga 1 juta tanpa kehilangan bagian pentingnya. Anda dapat melihat perubahan sebelum dan setelah kompresi pada gambar di bawah ini. Anda masih bisa melihat bentuk asli bangunannya dalam gambar yang terkompresi kan?

Kompresi gambar dari 16 juta warna menjadi 16 warna saja! (VanderPlas, 2016)
Anda bisa membaca ulasan serupa tentang k-Means oleh Jake VanderPlas di sini.

Terima kasih atas penjelasannya!
Btw, kumau tanya.. k-means ini kan pake Euclidean distance ya. Berarti ini cuma bisa diterapkan buat numerical data? Gimana kalo misalnya dalam 1 dataset ada campuran categorical/numerical data type? Gimana cara menghitung centroid di categorical data? Atau mungkin ada teknik lain yang lebih sesuai?
SukaSuka
Kita bisa kok pakai k-means untuk variabel kategorikal. Jika variabelnya biner (TRUE atau FALSE), langsung bisa dianggap seperti variabel numerik, yaitu dijadikan 1 atau 0. Jika variabelnya multinomial, biasanya dikonversi dulu menjadi one-hot encoding (https://scikit-learn.org/stable/modules/preprocessing.html#encoding-categorical-features). Misalnya untuk variabel “warna” dengan nilai merah, biru, dan hijau, masing-masing nilai menjadi variabel biner sendiri yaitu “warna_merah”, “warna_biru”, dan “warna_hijau”.
SukaSuka