Dua, tiga bulan lagi kalendar akademik tahun ajaran baru akan dimulai. Bagi mereka yang akan kuliah, sepertinya waktu-waktu ini sangat pas dialokasikan untuk persiapan menghadapi perkuliahan. Di samping persiapan administrasi kuliah dan tempat tinggal (untuk yang berkuliah di luar kampung halaman), ada baiknya kita juga mempersiapkan otak kita agar nantinya lebih mudah menyerap materi kuliah. Salah satu caranya yaitu dengan mengulas (ulang) subjek-subjek yang relevan dengan materi kuliah. Walhasil, harapannya kita bisa lebih fokus mempelajari apa yang disuguhkan dosen di kelas, ketimbang sibuk mengejar ketertinggalan materi yang seharusnya sudah kita kuasai sebelum kuliah dimulai (prerequisites).
Dalam artikel ini penulis akan mencoba memberi tips tentang subjek apa saja yang menurut penulis paling membantu mengikuti kuliah S2 pembelajaran mesin. Dengan gaya hipwee. Mungkin pembaca berpikir, “Oh, pasti subjeknya tentang algoritma atau ngoding” atau subjek-subjek ilmu komputer lainnya. Hmm, meskipun tentunya ilmu komputer dan kemampuan menulis program tidak bisa kita abaikan, setidaknya ada 3 subjek lain yang sangat sangat krusial dalam kuliah pembelajaran mesin. Dan ketiganya berasal dari ranah matematika.
Apakah ketiga subjek itu?
Probabilitas dan Statistika
Yang pernah mendalami pembelajaran mesin pasti tahu bahwa yang menjadi dasar dari berbagai algoritma pembelajaran mesin adalah prinsip-prinsip probabilitas dan statistika. Prinsip itu ada di mana-mana! Mulai dari regresi, klasifikasi, pengelompokan, hingga yang paling mutakhir, deep learning.
Konsep sebaran probabilitas, misalnya distribusi normal, merupakan komponen utama dalam berbagai model supervised learning, di antaranya dalam model regresi linear dan model Naive Bayes. Konsep variabel acak berkaitan langsung dengan fitur atau dimensi dalam pembelajaran mesin, dan independensi antar variabel acak juga kerap dijadikan asumsi pemodelan. Contohnya, rantai Markov berasumsi bahwa nilai variabel saat ini (Xt) bergantung hanya pada nilai variabel tersebut pada waktu sebelumnya (Xt-1), alias independen terhadap nilai variabel pada waktu-waktu yang lebih lampau (Xt-2, Xt-3, …, X0).
Konsep lain dari probabilitas dan statistika yang tidak kalah pentingnya dalam pembelajaran mesin adalah konsep inferensi dan estimasi parameter. Misalnya dalam regresi linear (maafkan saya regresi linear, kamu sudah saya abuse sebagai contoh), kita ingin mengestimasi parameter regresi, yaitu parameter w0, w1, …, wp untuk variabel 1,…, p dan intercept. Bagaimana caranya? Salah satunya dengan metode maximum likelihood estimation (MLE). Usut punya usut, jika parameter regresi diestimasi dengan MLE, hasilnya menjadi ordinary least squares regression (OLS). Menariknya, metode estimasi yang berbeda untuk model yang sama bisa menghasilkan nilai parameter yang berbeda. Metode estimasi maximum a posteriori (MAP), yang merupakan metode Bayesian, akan menghasilkan ridge regression.
Masih banyak lagi contoh terapan estimasi parameter dalam pembelajaran mesin, dan masih sangat banyak lagi konsep probabilitas dan statistika yang dimanfaatkan dalam pembelajaran mesin. Kalau kamu hanya punya waktu untuk mengulas satu subjek sebelum memulai kuliah S2 pembelajaran mesin, penulis sarankan untuk memprioritaskan probabilitas dan statistika. Tidak perlu khawatir jika model-model yang dicontohkan di atas terdengar asing; jika kita menguasai prinsip probabilitas dan statistika, seharusnya tidak terlalu sulit untuk bisa memahami model-model tersebut.
Belajar dari mana: Dengar-dengar kuliah Harvard Stat110: Probability sangat bagus untuk belajar probabilitas (dan statistika), baik untuk pemula atau yang sudah lumayan berpengalaman. Demikian juga dengan teks yang digunakan dalam kuliahnya: Introduction to Probability.
Aljabar Linear
Kapan sih kita berhadapan dengan problem pembelajaran mesin yang hanya berkutat dengan 1 variabel bebas? Sepertinya jauh lebih mudah ya kalau cuma ada 1 variabel bebas (tentu ada beberapa pengecualian, misalnya untuk data deret waktu). Namun sayang sekali, hampir semua problem pembelajaran mesin berkaitan dengan data banyak variabel, termasuk data berupa gambar atau teks.
Di mana kita punya banyak variabel serta banyak poin data atau sampel, di situ kita menggunakan vektor dan matriks. Nah, vektor dan matriks ini dipelajari dalam cabang matematika yang dinamakan aljabar linear. Berbagai operasi terhadap vektor dan matriks dilakukan dalam komputasi pembelajaran mesin, mulai dari operasi aljabar, normalisasi, faktorisasi matriks atau reduksi dimensi, hingga kalkulus vektor dan matriks (yang dikenal juga dengan istilah kalkulus variabel banyak).
Sebuah dataset juga kerap direpresentasikan dalam bentuk tabel, yang ekuivalen dengan matriks. Masing-masing baris dalam tabel tersebut merupakan sebuah poin data, yang ekuivalen dengan vektor. Jika dimensi matriks adalah n baris x p kolom, atau n poin data dengan p variabel bebas, maka matriks atau dataset tersebut bisa dikonstruksikan ke dalam ruang p-dimensi, dengan tiap poin data menjadi sebuah titik dalam ruang. Lebih lanjut, kita bisa mentransformasikan matriks atau ruang p-dimensi tersebut sehingga dataset-nya menjadi lebih sesuai untuk model yang akan kita gunakan. Proses ini disebut feature engineering.
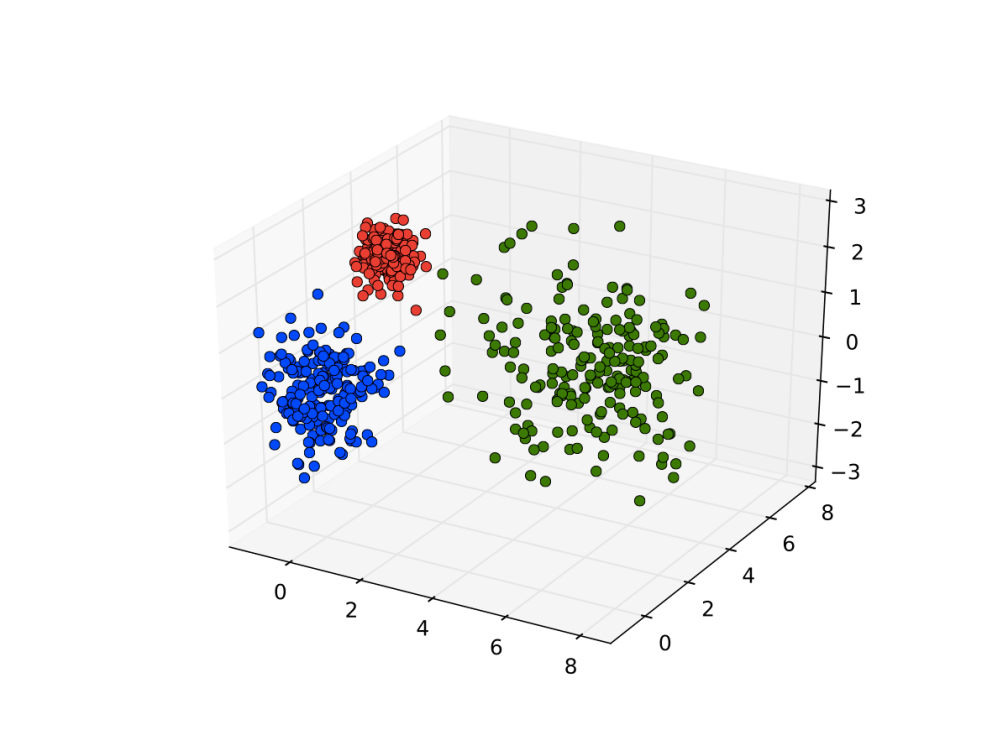
Contoh representasi dataset (matriks) untuk problem klasifikasi dalam ruang 3-dimensi. Warna poin data menyatakan kelas data tersebut. Gambar diambil dari solem’s vision blog
Aplikasi lain aljabar linear dalam pembelajaran mesin berasal dari sisi praktis, yaitu kemudahan penulisan atau notasi (notational advantage). Aljabar linear memungkinkan kita menulis fungsi dengan banyak variabel secara lebih mudah. Contohnya, bagaimana coba kita menulis probability density function dari distribusi normal multivariabel tanpa notasi matriks atau vektor? Selain kemudahan penulisan, banyak bahasa pemrograman yang mendukung operasi tervektorisasi, baik secara built-in maupun melalui pustaka. Operasi tervektorisasi ini umumnya lebih mudah untuk ditulis dan lebih natural untuk dibaca, ditambah lagi lebih cepat eksekusinya. Sering kali, operasi yang bisa ditulis dalam notasi vektor membutuhkan perulangan (e.g. for loop) jika ditulis tanpa notasi vektor. Contoh operasi perkalian matriks dengan dan tanpa vektorisasi bisa dilihat di sini.
Belajar dari mana: Kuliah daring MIT OCW 18.06: Linear Algebra banyak direkomendasikan untuk belajar aljabar linear, berikut buku yang ditulis oleh profesornya (Gilbert Strang): Introduction to Linear Algebra. Untuk kuliah yang lebih mendasar, terdapat 2 MOOC lain, yaitu Coding the Matrix di Coursera dan Linear Algebra – Foundations to Frontiers di edx.
Kalkulus
Kata siapa kamu tidak akan ketemu lagi sama kalkulus? Kalkulus itu ada di mana-mana. Paling tidak, kalkulus ada di kuliah S2 pembelajaran mesin.
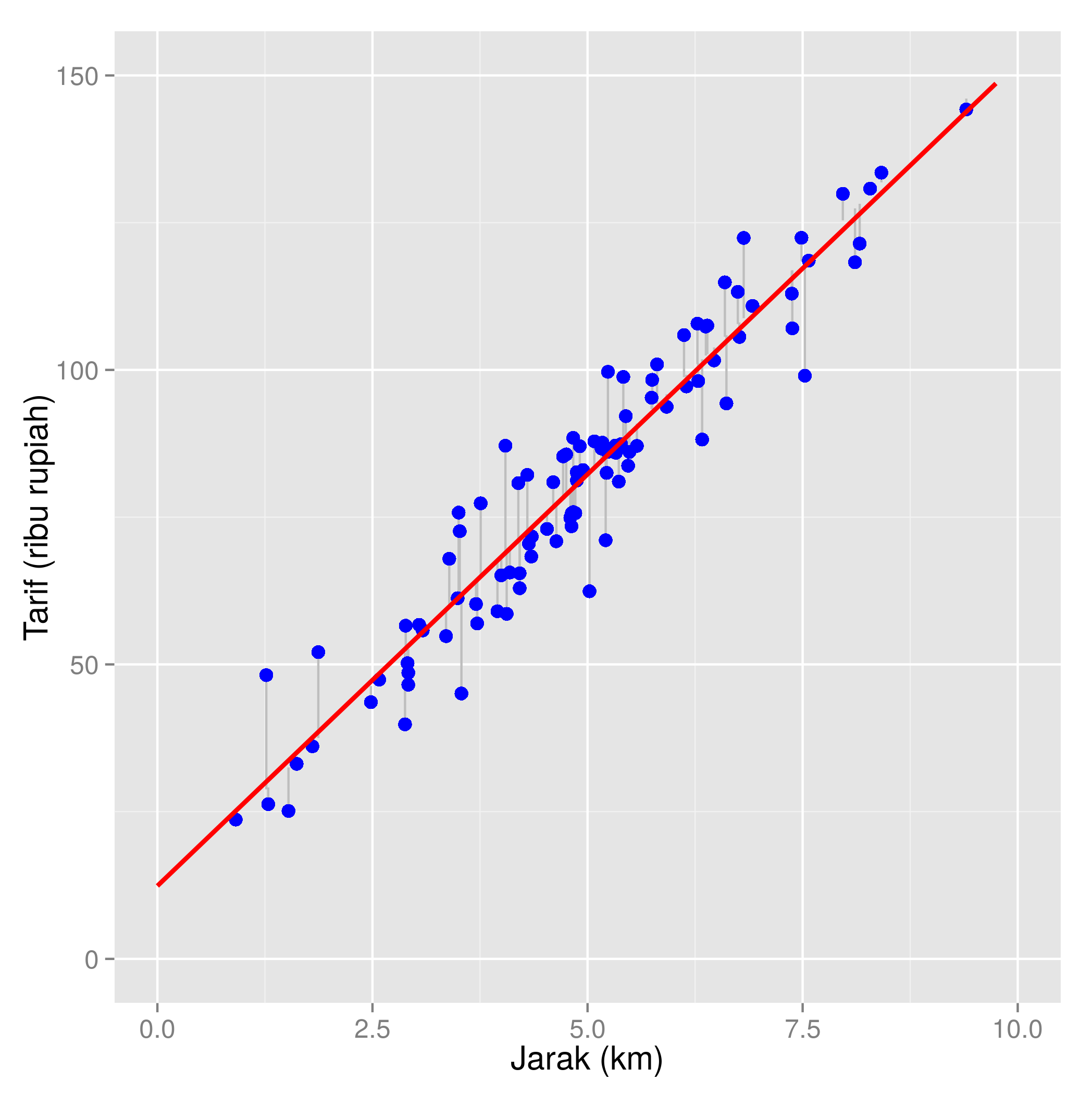
Sebelumnya penulis sudah memberi contoh singkat estimasi parameter dengan MLE. Melalui MLE, dihasilkan parameter-parameter yang memaksimalkan fungsi likelihood (atau meminimalkan fungsi likelihood negatif), berdasarkan data yang kita miliki. Bagaimana cara memaksimalkan sebuah fungsi? Ingat-ingat kembali kalkulus atau matematika SMA. Ya, jawabannya adalah: diferensial. Banyak sekali problem pembelajaran mesin yang pada akhirnya bisa diformulasikan sebagai permasalahan optimasi, misalnya optimasi fungsi likelihood ataupun optimasi galat (contoh optimasi galat dalam regresi linear bisa dilihat di sini). Asumsinya adalah, jika terdapat suatu titik dalam range fungsi yang merupakan optimum global, maka secara teoretis parameter yang menghasilkan optimum global merupakan parameter “terbaik” untuk data yang kita miliki. Jika tidak ada optimum global, digunakan metode optimasi lain seperti gradient descent, yang juga memanfaatkan diferensial dalam komputasinya.
Tak terpisahkan dari diferensial adalah integral. Aplikasi integral dalam pembelajaran mesin terutama berkaitan dengan sebaran probabilitas dan probabilitas marginal. Misalnya, dalam metode Bayesian, probabilitas posterior P(Y | X) didefinisikan sebagai probabilitas gabungan P(X, Y) = P(X | Y) * P(Y), yang dinormalisasi (i.e. dibagi) dengan probabilitas marginal P(X). Biasanya kita hanya mengetahui rumus P(X | Y) dan P(Y). Bagaimana memperoleh rumus probabilitas marginal P(X) agar kita bisa menghitung probabilitas posterior P(Y | X)? Yaitu dengan memarginalisasi variabel Y dalam persamaan P(X, Y). Jika Y merupakan variabel kontinu, maka marginalisasi dilakukan dengan menghitung integral. Contoh lain pemanfaatan integral dalam pembelajaran mesin adalah pada model probabilistik grafis.
Selain diferensial dan integral, jangan lupa juga dengan dua fungsi yang sangat esensial dalam kalkulus: logaritma dan eksponen. Misalnya, logaritma dari fungsi likelihood sering digunakan untuk mempermudah komputasi optimasi, baik di atas kertas (ingat bahwa salah satu identitas logaritma adalah “memecah” perkalian) maupun di dalam komputer (untuk mencegah arithmetic overflow). Eksponen sendiri banyak ditemukan dalam sebaran probabilitas, dan ada “keluarga” distribusi khusus yang didasarkan pada fungsi eksponen. Konsep-konsep lain dari kalkulus seperti asimtot dan limit juga ada dalam pembelajaran mesin.
Belajar dari mana: Di Coursera ada 2 kuliah yang oke untuk belajar kalkulus: Calculus One dan Calculus: Single Variable. Untuk kalkulus variabel banyak, kita bisa belajar dari MIT OCW 18.02: Multivariable Calculus.
Selamat belajar dan selamat menjadi mahasiswa lagi!
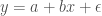

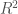


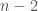

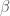

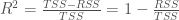



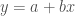

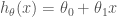
 ) — yang didapatkan dari model yang dibentuk (
) — yang didapatkan dari model yang dibentuk ( ) — dengan nilai hasil observasi (observed;
) — dengan nilai hasil observasi (observed;  ). Jadi, dapat ditulis sebagai
). Jadi, dapat ditulis sebagai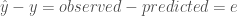


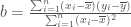

 dan
dan  adalah nilai rata-rata dari y dan x berdasarkan sampel yang diambil.
adalah nilai rata-rata dari y dan x berdasarkan sampel yang diambil.