Di pos sebelumnya, kita sudah membahas tentang regresi linear. Nah, kali ini kita akan membahas bagaimana mengevaluasi model yang sudah dihasilkan oleh regresi linear tersebut. Dengan kata lain, seberapa “akurat” model yang kita hasilkan dalam memprediksi titik-titik data yang ada.
Evaluasi Akurasi Perkiraan Nilai Koefisien
Selalu ada galat ketika melakukan estimasi terhadap nilai koefisien dan menentukan fungsi regresi yang digunakan. Entah karena ketidaksesuaian fungsi regresi yang digunakan (diasumsikan linear, padahal kuadratis, misalnya), adanya data pencilan, atau karena adanya pengaruh variabel lain yang belum dimasukkan sebagai pertimbangan untuk menyusun model regresinya. Oleh karena itu, fungsi linear yang didefinisikan sebelumnya dapat ditulis ulang sebagai
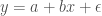
dengan 
Nah, kita perlu mengingat bahwa data yang kita gunakan dalam memperkirakan nilai koefisien ini merupakan sekelompok sampel — bukan populasi. Oleh karena itu, dikenal lah benda-benda bernama confidence interval dan p-value yang digunakan untuk mengetahui apakah parameter yang digunakan untuk memprediksi y (nilai a dan b) itu signifikan atau hanya kebetulan saja. Walakin, beberapa orang sudah meninggalkan confidence interval dan p-value dewasa ini. Sedikit gambaran mengapa nilai-nilai itu ditinggalkan bisa dilihat di artikel ini dan komik ini.
Evaluasi Akurasi dari Model
Ada beberapa cara yang dapat digunakan untuk mengevaluasi model (fungsi) yang sudah dihasilkan. Intinya, kita ingin melihat seberapa jauh model yang kita hasilkan cocok dengan data yang tersedia. Berdasarkan kitab kuning ilmu statistik [1], ada dua metode yang secara umum dilakukan untuk mengevaluasi model yang dihasilkan: residual standard error (RSE) dan 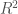
Residual Standard Error
Ingat bahwa di bagian sebelumnya sempat dibahas tentang munculnya

dengan nilai 
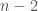

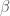
R²
Sementara RSE hanya mengandalkan selisih dari nilai yang diprediksi dan nilai yang diobservasi, 
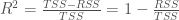
Nilai
Root Mean Squared Error
Terakhir, cara yang juga biasanya digunakan untuk mengevaluasi model regresi linear adalah dengan RMSE. Cara ini juga dikenal dengan nama root mean squared deviation (RMSD). Seperti dapat diperkirakan dari namanya, RMSE atau RMSD dihitung dengan menguadratkan error (predicted – observed) dibagi dengan jumlah data (= rata-rata), lalu diakarkan. Secara matematis, rumusnya ditulis sebagai berikut

yang sebetulnya juga bisa dilihat sebagai

Nah, dengan gambaran tersebut, semoga Anda sudah bisa lebih memahami gambaran mengenai simple linear regression. Untuk bagian berikutnya, kami akan mencoba memberikan contoh kode program untuk regresi linear. Sementara itu, selamat mencoba-coba!
—
Referensi
[1] James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning (p. 68). New York: Springer.
