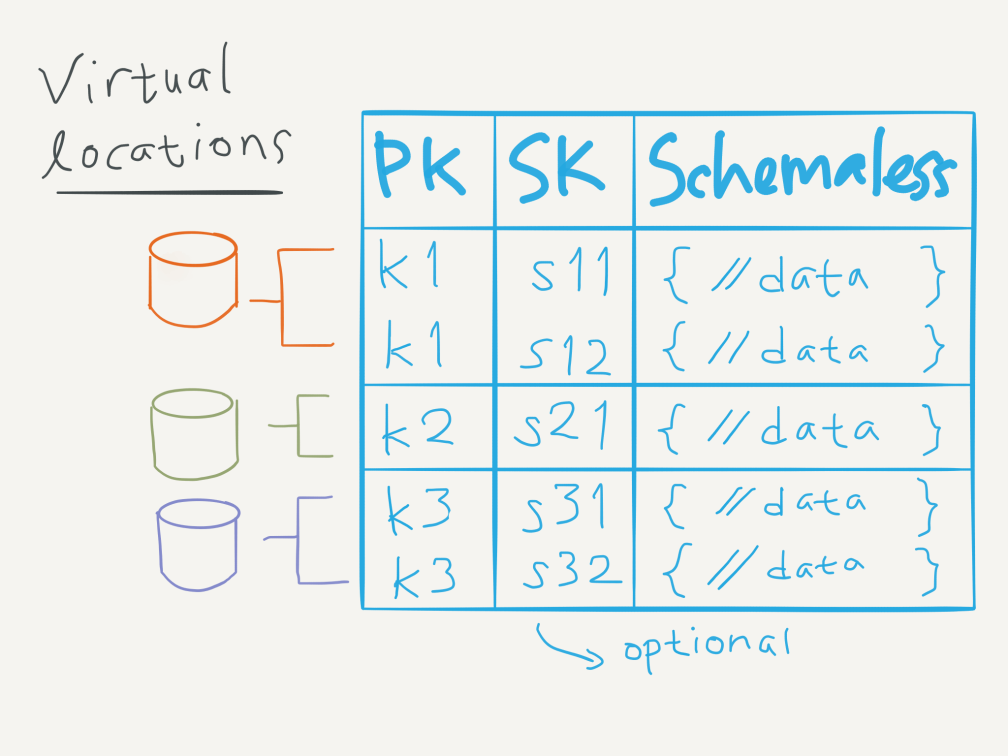
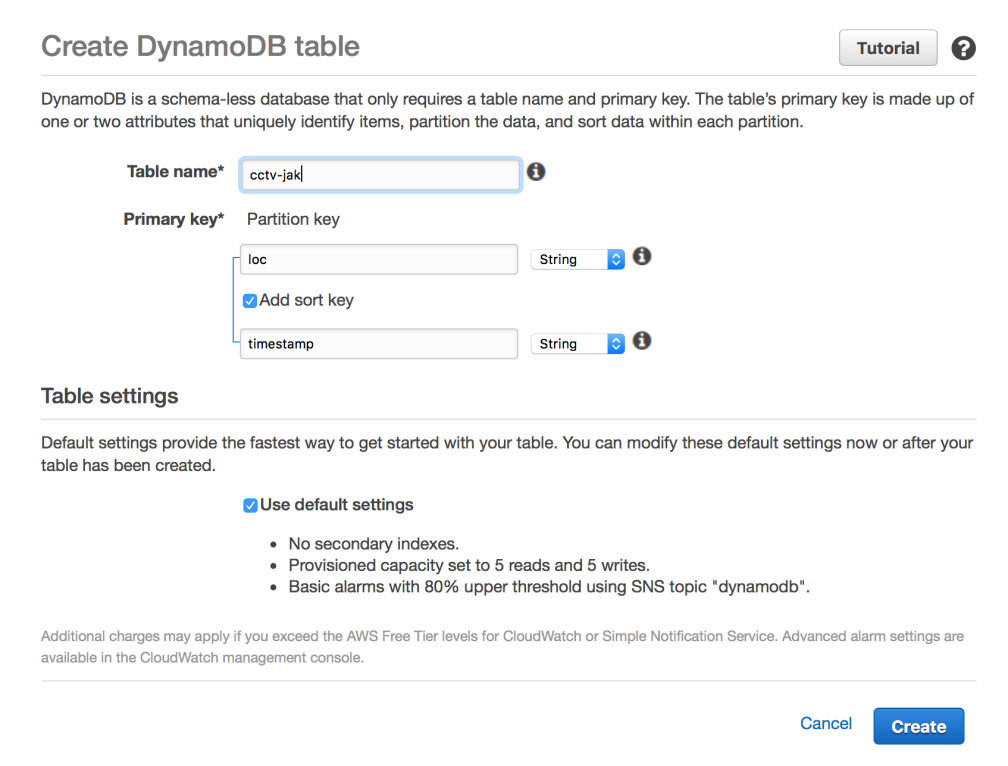
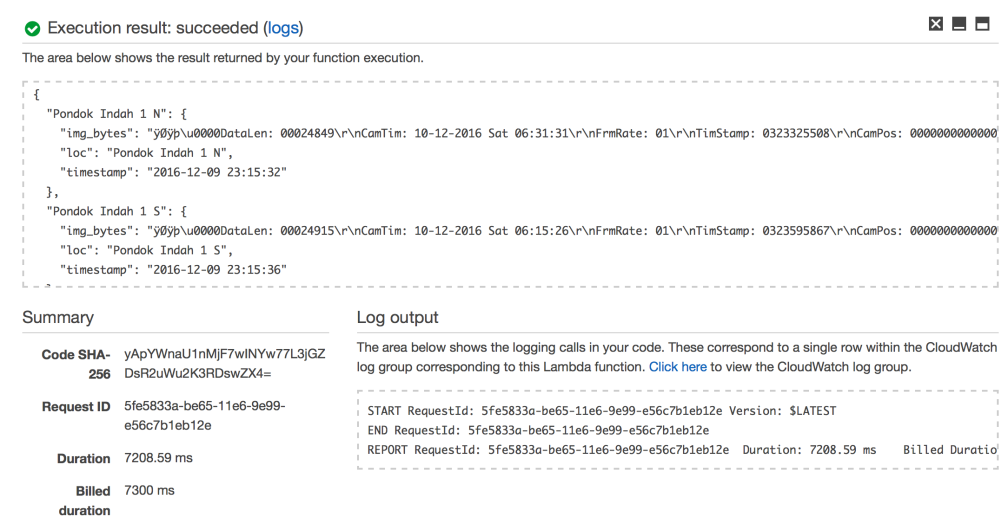
Dalam dua artikel sebelumnya, Serverless Scraping Semurah Tahu Tempe dengan AWS Lambda dan Managed Database Semurah Tahu Tempe dengan Amazon DynamoDB, kita sudah membahas metode “murahan” untuk scraping CCTV Transjakarta menggunakan AWS Lambda dan Amazon DynamoDB.
Sekarang saatnya membangun model machine learning yang bisa mendeteksi kemacetan dari jepretan CCTV. Artikel ini sangat terinspirasi (i.e. nyontek) artikel dari blog keras.io: Building Powerful Image Classification Models Using Very Little Data.
Jadi ceritanya, kami sudah mengumpulkan 53.000 jepretan dari 15 CCTV Transjakarta selama periode 1 November sampai 19 Desember 2016. Kami melabeli sendiri sekitar 15.000 jepretan yang diambil pukul 05.00-23.00 WIB, mana yang macet dan mana yang tidak. Hasil pengumpulan datanya kurang lebih seperti ini:
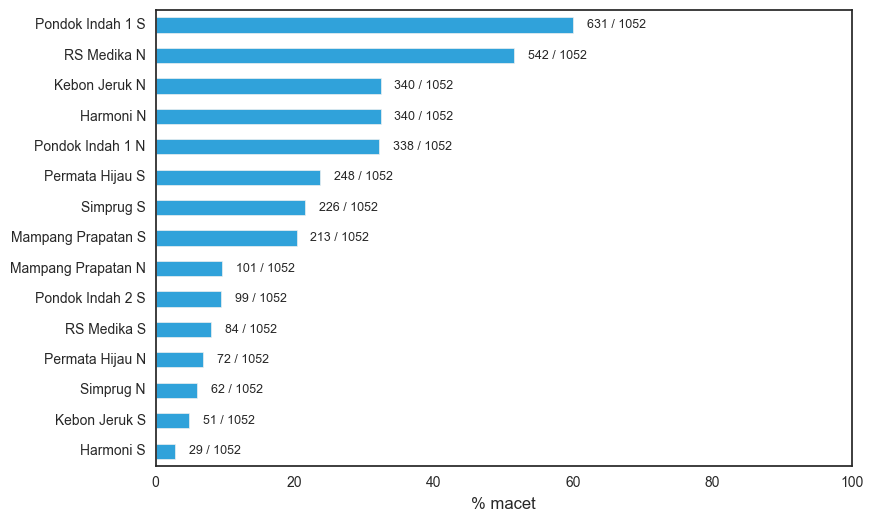
Statistik kemacetan per halte Transjakarta. Halte paling macet tidak lain adalah Pondok Indah 1 Selatan, di mana 631 dari 1.052 (~60%) jepretan CCTV kami labeli “Macet”.
Dengan data di tangan, langsung saja kita buat model machine learning-nya!
Keras Applications
Keras Applications adalah salah satu modul dalam pustaka Keras yang menyediakan arsitektur berbagai model deep learning ternama. Asyiknya lagi, model-model itu sudah dilatih out of the box. Dengan kata lain, menggunakan Keras Applications kita bisa membuat sistem cerdas (misalnya deteksi gambar / image recognition) tanpa harus mengumpulkan data sama sekali atau melatih model berminggu-minggu pada GPU cluster. Model deteksi gambar Keras Applications juga bisa dipakai untuk mengekstraksi fitur-fitur dari gambar, yang akan dibahas lebih lanjut dalam artikel ini. Per Desember 2016, pilihan model yang tersedia dalam Keras Applications antara lain Xception, VGG16 dan VGG19, ResNet50, dan InceptionV3 untuk deteksi gambar serta MusicTaggerCRNN untuk deteksi musik. Keras sendiri sebenarnya “cuma” antarmuka yang memudahkan pemrograman; segala komputasi model dilakukan oleh pustaka backend, yaitu TensorFlow atau Theano.
Jadi, bagaimana cara memakai Keras Applications untuk melatih model machine learning? Seperti dijelaskan dalam blog Keras, terdapat 2 cara untuk ini. Yang paling mudah adalah dengan menggunakan model Keras Applications tanpa lapisan terakhir sebagai ekstraktor fitur. Karena hanya sampai lapisan sebelum terakhir alias bottleneck layer saja, keluaran yang kita terima dari model bukan berupa kelas gambar (anjing vs kucing vs burung, dan sebagainya), melainkan berupa tensor atau array multidimensi. Tensor ini mengandung informasi atau fitur mengenai gambar yang bisa dimanfaatkan lebih lanjut. Nah, cara pertama memakai Keras Applications adalah dengan mengekstraksi tensor dari sekumpulan gambar, yang kemudian dijadikan data latih model machine learning untuk task yang kita inginkan.
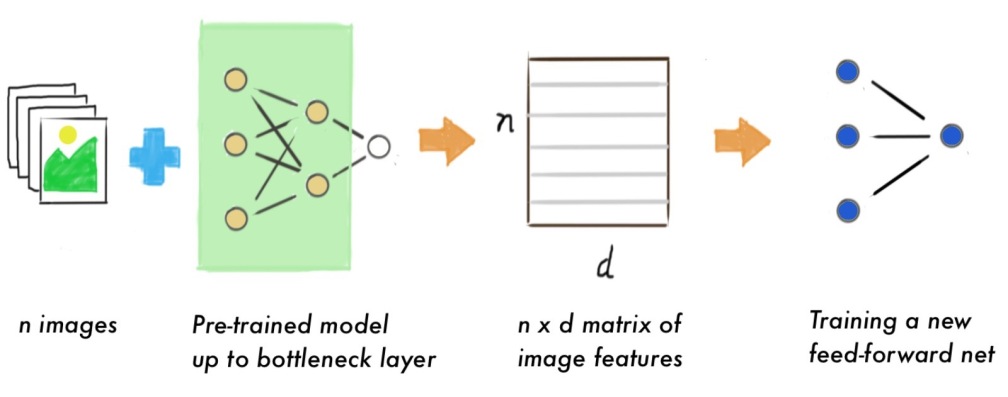
Menggunakan pre-trained model sebagai ekstraktor fitur
Cara kedua lebih sulit, yaitu dengan melatih ulang beberapa lapisan terakhir model Keras Applications (disebut juga retraining atau fine-tuning). Umumnya yang dilatih ulang hanya bottleneck layer-nya saja, karena semakin banyak lapisan yang dilatih, semakin banyak juga jumlah data dan kemampuan komputasi yang dibutuhkan. Namun jika kita punya data yang banyak dan komputer yang canggih, melatih ulang beberapa lapisan model biasanya akan memberi hasil yang lebih akurat.
Tentu saja (supaya gampang) artikel ini memakai cara pertama, hehehe.
Pemodelan Hasil ResNet50
Kode berikut diadaptasi dari dokumentasi Keras Applications dan berfungsi untuk mengekstraksi fitur gambar (2.048 dimensi) menggunakan model ResNet50. Ketika pertama kali dijalankan, kode ini akan mengunduh parameter model ResNet50 yang sudah dilatih oleh pengembang Keras. Saking banyaknya parameter, ukuran berkas yang diunduh sampai 90 MB lho!
| from keras.applications.resnet50 import ResNet50, preprocess_input | |
| from keras.preprocessing import image | |
| import numpy as np | |
| resnet = ResNet50(include_top=False) | |
| def extract_features(img_paths, batch_size=64): | |
| """ This function extracts image features for each image in img_paths using ResNet50 bottleneck layer. | |
| Returned features is a numpy array with shape (len(img_paths), 2048). | |
| """ | |
| global resnet | |
| n = len(img_paths) | |
| img_array = np.zeros((n, 224, 224, 3)) | |
| for i, path in enumerate(img_paths): | |
| img = image.load_img(path, target_size=(224, 224)) | |
| img = image.img_to_array(img) | |
| img = np.expand_dims(img, axis=0) | |
| x = preprocess_input(img) | |
| img_array[i] = x | |
| X = resnet.predict(img_array, batch_size=batch_size, verbose=1) | |
| X = X.reshape((n, 2048)) | |
| return X |
Bisa dilihat, dengan Keras Applications kode deep learning jadi sangat sederhana bukan?
Menggunakan MacBook Pro keluaran pertengahan 2014 (Intel Core i5 2.6 GHz, RAM 8 GB, 4 thread, penyimpanan SSD, dan tidak ada GPU), kode di atas dapat mengekstraksi fitur sekitar 100 gambar setiap menitnya. Data kami seluruhnya ada 15.000 gambar, jadi total waktu yang diperlukan untuk ekstraksi fitur mencapai 2.5 jam 😱
Selanjutnya, hasil eksekusi fungsi extract_features tersebut menjadi data latih untuk membangun model deteksi kemacetan. Karena data latihnya tidak lagi berupa sekumpulan gambar melainkan sudah berbentuk matriks (n gambar * 2.048), kita sebetulnya bisa memakai model supervised learning apa pun untuk task ini, misalnya XGBoost atau SVM. Namun, kita ikuti saja cara dalam blog Keras, yaitu menggunakan feed-forward neural network sederhana: 1 hidden layer dengan 256 simpul ditambah 1 dropout layer. Untuk fungsi objektif dipilih binary cross entropy yang dioptimasi dengan algoritma Adam. (Banyak ya konsep-konsep neural network yang mungkin asing bagi pembaca. Semoga kapan-kapan kami bisa membahas konsep ini dalam artikel terpisah.)
Kode untuk melatih modelnya sebagai berikut:
from keras.layers import Dense, Dropout
from keras.models import Sequential
from sklearn.model_selection import train_test_split
# X, y = code for obtaining image features and labels
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8)
model = Sequential()
model.add(Dense(256, activation='relu', input_dim=2048))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile('adam', 'binary_crossentropy', metrics=['accuracy', 'fmeasure'])
model.fit(X_train, y_train, validation_data=(X_test, y_test))
Dengan komputer yang sama, kode di atas selesai dieksekusi dalam 1-2 menit saja! Berikut kira-kira pesan yang dikeluarkan Keras selama model dilatih.
Train on 11835 samples, validate on 3945 samples Epoch 1/10 11835/11835 [==============================] - 8s - loss: 0.2065 - acc: 0.9189 - fmeasure: 0.7886 - val_loss: 0.1172 - val_acc: 0.9569 - val_fmeasure: 0.8924 Epoch 2/10 11835/11835 [==============================] - 7s - loss: 0.1358 - acc: 0.9492 - fmeasure: 0.8677 - val_loss: 0.0952 - val_acc: 0.9617 - val_fmeasure: 0.8994 ... Epoch 9/10 11835/11835 [==============================] - 6s - loss: 0.0846 - acc: 0.9674 - fmeasure: 0.9157 - val_loss: 0.0799 - val_acc: 0.9660 - val_fmeasure: 0.9125 Epoch 10/10 11835/11835 [==============================] - 6s - loss: 0.0774 - acc: 0.9715 - fmeasure: 0.9263 - val_loss: 0.0824 - val_acc: 0.9673 - val_fmeasure: 0.9097
Evaluasi
Nah, sekarang model kita sudah siap digunakan untuk memprediksi kemacetan! Tapi sebelumnya, kita evaluasi dulu seberapa bagus prediksinya, baik untuk data latih maupun data uji. Metrik-metrik yang kita perhatikan antara lain akurasi, presisi, recall, F1, dan negative predictive value (NPV).
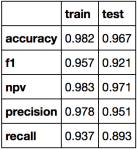
Hasil evaluasi model. Dengan total waktu latih hanya 1-2 menit, lumayan banget kan hasilnya?
Secara umum, hasil evaluasi pada data latih lebih baik dibanding pada data uji (ya iya lah!). Keseluruhan metrik juga tidak mengalami penurunan drastis pada data uji, dengan penurunan terbesar terjadi pada recall yang berkurang sekitar 4.4%. Bisa dibilang modelnya tidak overfit terlalu parah.

Contoh prediksi model. Memang cukup sulit ya menentukan kemacetan dari 1 jepretan saja
Evaluasi per halte
Sekilas hasil di atas tampak memuaskan. Sayangnya, begitu kami telaah hasil evaluasi data uji untuk masing-masing halte, ternyata pada sebagian halte F1-nya tidak sampai 85%:
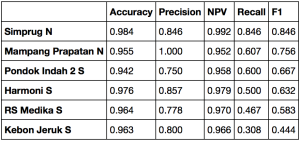
Hasil evaluasi kurang bagus untuk sebagian halte 😞
Untuk halte-halte ini, presisi dan NPV-nya sebetulnya tidak begitu rendah, walau masih di bawah angka rata-rata seluruh halte. Yang bermasalah adalah recall-nya. Pada halte Kebon Jeruk Selatan, recall-nya bahkan hanya mencapai 31%!
Kami menduga hasil evaluasi untuk halte-halte tersebut tidak baik karena memang labelnya tidak seimbang. Buktinya, keenam halte tersebut termasuk dalam 7 halte dengan tingkat kemacetan terendah dalam data kami, dengan jumlah label positif kurang dari 10% (lihat kembali grafik batang persentase kemacetan di atas). Scatter plot di bawah juga menunjukkan hubungan yang cukup linear antara (logaritma) persentase kemacetan halte dengan angka F1 model pada data uji (korelasi ~75%).
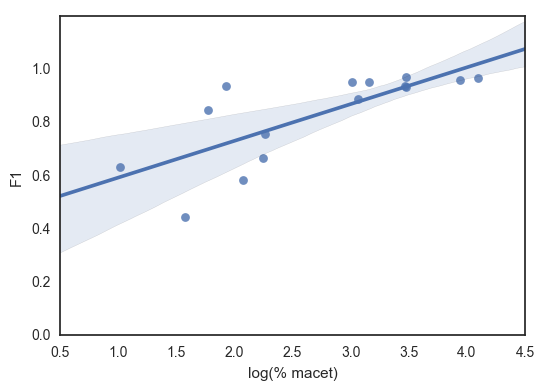
Perbandingan tingkat kemacetan (skala-log) dengan F1 pada data uji
Jika dipikir-pikir, ini sebetulnya good problem ya, karena semakin sering suatu jalan macet, modelnya semakin akurat memprediksi kemacetan di jalan itu. Karena presisinya juga cukup baik, kita bisa benar-benar percaya kalau model mengatakan jalan sedang macet. Mungkin pembaca ada yang tertarik untuk menelusuri lagi?
Kemampuan generalisasi model
Evaluasi di atas dilakukan berdasarkan metode train-test split biasa. Sejatinya, kita menginginkan model yang memiliki kemampuan generalisasi yang baik: ketika dipakai untuk halte atau CCTV yang baru (tidak ada di data latih), akurasi model enggak jelek-jelek amat. Nah, percobaan terakhir yang kami lakukan adalah melatih model tanpa data suatu halte sama sekali, yang kemudian diujikan pada data halte tersebut. Contohnya, dilatih model tanpa data halte Pondok Indah Selatan, lalu diujikan pada data halte Pondok Indah Selatan; dilatih model lain tanpa data halte Mampang Prapatan Utara, lalu diujikan pada data halte Mampang Prapatan Utara, dan seterusnya. Jadi seperti cross-validation berdasarkan halte begitu.
Hasilnya seperti berikut:
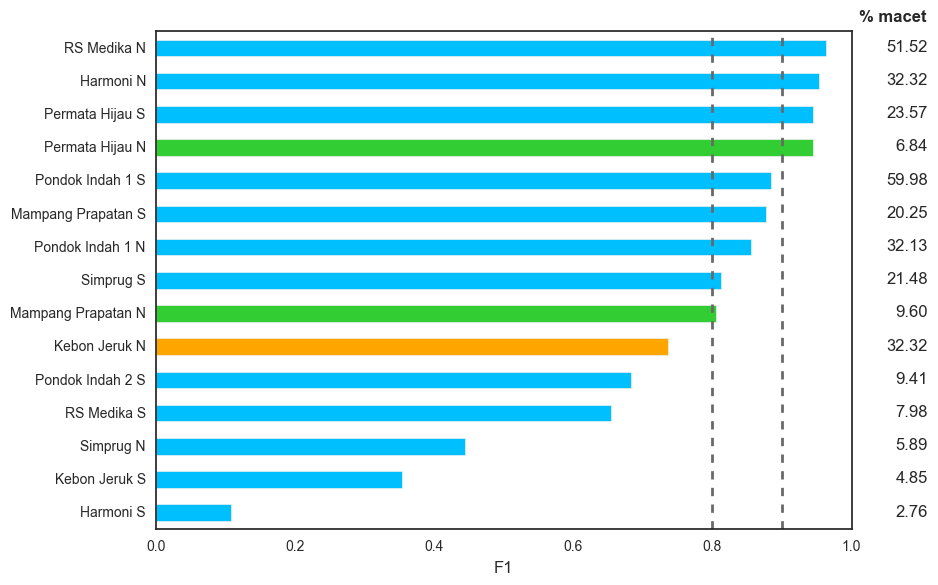
Hasil evaluasi (F1) menggunakan metode cross-validation per halte
Ternyata modelnya berhasil mencapai F1 cross-validation lebih dari 90% hanya pada 4 dari 15 halte 😞, dan lebih dari 80% pada 9 dari 15 halte. Lagi-lagi halte yang “bermasalah” adalah halte dengan tingkat kemacetan rendah, seperti Pondok Indah 2 Selatan dan RS Medika Selatan. Yang menarik untuk diamati adalah halte Permata Hijau Utara dan Mampang Prapatan Utara, di mana tingkat kemacetannya rendah (masing-masing 6,84% dan 9,60%) namun F1-nya tinggi. Dan sebaliknya, halte Kebon Jeruk Utara tingkat kemacetannya tinggi (32,32%) namun F1-nya cukup rendah, sekitar 74%. Dari hasil di atas, agaknya masih perlu dilakukan perbaikan pemodelan agar kemampuan generalisasi model bisa jauh lebih baik, misalnya F1 cross-validation di atas 90% semua hehehe.
Pertanyaan generalisasi lainnya adalah: apakah model sama akuratnya untuk deteksi di siang hari ketimbang deteksi di malam hari? Karena saya sudah lelah, akan saya simpan saja pertanyaan ini untuk percobaan-percobaan selanjutnya (kalau saya tidak malas).
Penutup
Sebetulnya masih sangat banyak lagi yang bisa dieksplorasi untuk memperbaiki akurasi model, misalnya:
- Implementasi metode khusus untuk menangani label yang tidak seimbang
- Latih ulang beberapa lapisan terakhir model Keras Applications
- Coba memakai model lain yang tersedia di Keras Applications, seperti InceptionV3
- Kumpulkan lagi data dari lebih banyak halte
- Kumpulkan lagi data yang sudah otomatis teranotasi, misalnya dengan API Flickr
- Buat data sintetis dari data yang sudah ada, misalnya dengan modul pemrosesan gambar Keras
- Gunakan feed-forward neural network yang lebih kompleks
- Tuning lebih banyak lagi parameter neural network, misalnya tingkat regularisasi dan fungsi aktivasi
Ketiga artikel terakhir yang saya tulis menjelaskan metode pemodelan machine learning dari awal (pengumpulan data) sampai akhir (evaluasi model), menggunakan tools yang semuanya gratis atau “hampir” gratis. Saya sangat senang menulisnya, semoga bermanfaat dan pembaca juga senang membacanya.
Sampai jumpa di tahun 2017!