
Kembali lagi dengan pos Semurah Tahu Tempe. Sebelumnya kita sudah membahas serverless scraping dengan AWS Lambda. Kali ini kita akan membahas managed database semurah tahu tempe dengan Amazon DynamoDB.
Bagi yang belum familiar, managed database adalah layanan yang memungkinkan kita menggunakan fitur-fitur sistem basis data tanpa perlu melakukan instalasi software atau hardware apapun. Bisa dibilang managed database adalah database tanpa repot: kita tidak perlu menyediakan server, kita tidak perlu melakukan pembaruan versi database, kita bisa dengan mudah scale up dan scale down kapasitas database, dan jatuhnya juga bisa jadi lebih murah dibanding pakai database “konvensional”.
Salah satu managed database yang disediakan AWS adalah Amazon DynamoDB. DynamoDB berbasis NoSQL, di mana data disimpan dalam format key-value layaknya JSON. Memang fitur DynamoDB tidak selengkap database lainnya; misalnya, kita tidak bisa melakukan query agregasi di DynamoDB. 😦 Namun, karena kinerjanya yang baik serta kepraktisannya untuk digunakan dan di-scale up scale down, DynamoDB bisa menjadi pilihan yang tepat untuk aplikasi yang tidak memerlukan fitur lengkap dari database SQL. Lebih lengkapnya mengenai usage pattern DynamoDB bisa dibaca di pos ini.
Nah, seperti AWS Lambda, DynamoDB juga memiliki free tier tanpa ekspirasi. Kita bisa menyimpan data hingga 25 GB dengan kapasitas IO hingga 25 item * 100 kB per detik.

Free tier Amazon DynamoDB
Melanjutkan pos sebelumnya, mari kita buat scraper menggunakan pasangan emas DynamoDB dan AWS Lambda.
Scraping CCTV Transjakarta
Sudah beberapa tahun ini Jakarta Smart City memiliki web yang menampilkan kondisi berbagai fasilitas umum di Jakarta secara real-time dalam bentuk peta. Salah satu informasi yang bisa diakses dalam peta ini adalah live streaming CCTV di halte-halte Transjakarta. Contohnya, kita bisa menonton kondisi jalan di depan halte busway Pondok Indah di alamat ini (hint: jalannya sering banget macet).

Contoh rekaman CCTV Transjakarta halte Pondok Indah 1. Dulu saya mengarungi kemacetan ini setiap hari 😦
Karena sudah ada data terbuka yang bisa diakses secara real-time, bisa nggak ya kita buat program otomatis untuk mendeteksi kemacetan di berbagai lokasi di Jakarta? Supaya bisa menjawab pertanyaan ini, kita akan mengumpulkan screenshot dari video CCTV-CCTV Transjakarta dan menggunakannya sebagai data latih machine learning.
Menyetel tabel DynamoDB
Sebelum mulai scraping, kita perlu menyiapkan basis data di mana kita akan menyimpan hasil scraping nantinya. Data (i.e. item) dalam tabel DynamoDB disimpan dalam format JSON dan antar-item tidak diharuskan memiliki skema yang sama (ingat, DynamoDB adalah NoSQL). Hanya, setiap item wajib memiliki Partition Key yang digunakan (di balik layar) oleh AWS untuk membagi isi tabel ke dalam lokasi-lokasi terpisah dalam rangka meningkatkan kinerja. Selain Partition Key, kita juga bisa mendefinisikan Sort Key untuk mengurutkan item. Jadi, peletakan item dilakukan berdasarkan Partition Key, dan item-item dengan Partition Key yang sama diurutkan berdasarkan Sort Key. Partition Key (ditambah Sort Key) berperan seperti primary key dalam basis data SQL.
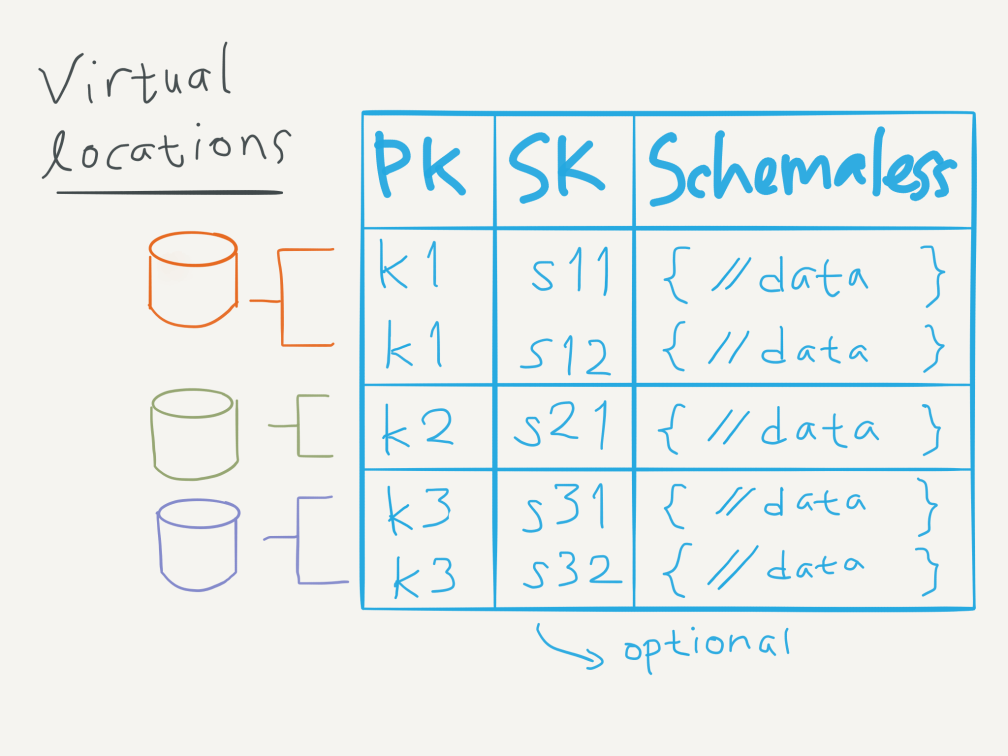
Ilustrasi skema penyimpanan tabel DynamoDB
Untuk data screenshot CCTV, kita definisikan loc sebagai Partition Key dan timestamp sebagai Sort Key. loc adalah kode lokasi CCTV (misalnya “Pondok Indah 1 N”) dan timestamp adalah waktu kita menjalankan scraping (misalnya “2016-11-30 08:19:30”). Data screenshot CCTV-nya sendiri akan disimpan dalam field img_bytes, namun dalam DynamoDB kita tidak perlu (bahkan tidak bisa) menspesifikasikan field selain Partition Key dan Sort Key.
Tabel DynamoDB bisa dibuat dengan meng-klik Create Table pada halaman utama DynamoDB di AWS. Kita gunakan pengaturan seperti di bawah ini, kemudian klik Create untuk membuat tabel.
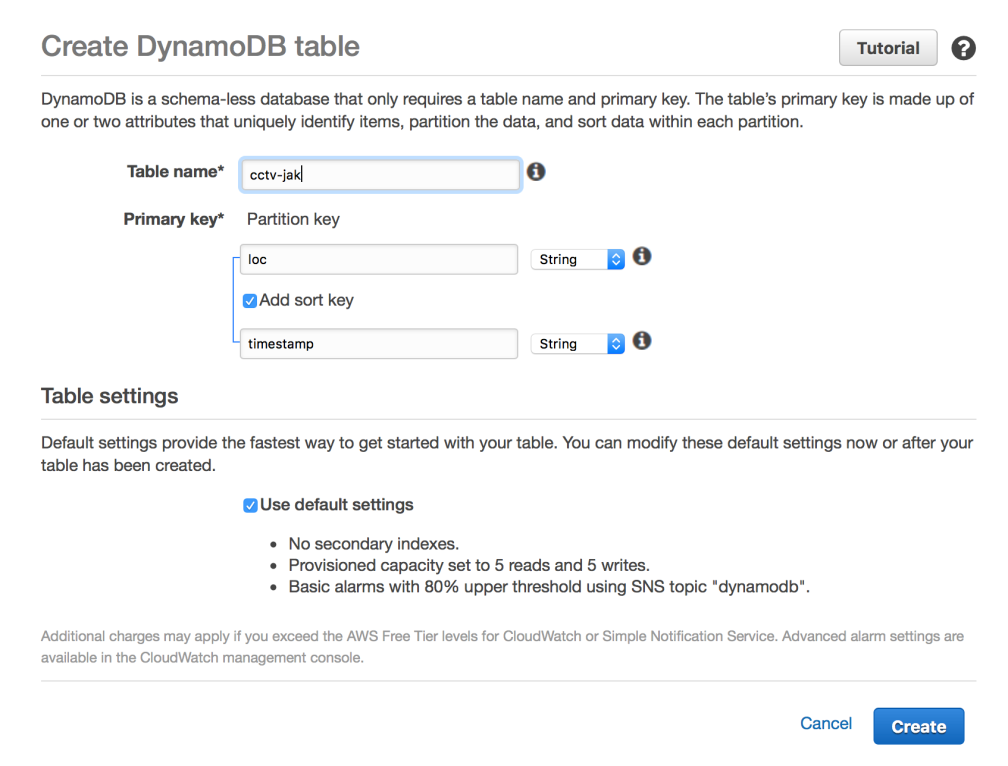
Pengaturan tabel DynamoDB untuk scraping CCTV Transjakarta
Lebih kurang 1 menit AWS akan selesai mem-provision tabel kita. Kita bisa melihat berbagai informasi mengenai tabel seperti Partition Key & Sort Key, jumlah item dalam tabel, dan total ukuran data yang disimpan. Untuk sekarang, catat Amazon Resource Name (ARN) tabel karena nantinya akan diperlukan untuk mengakses tabel dari fungsi Lambda.
Read Capacity dan Write Capacity
Jika kita menginstalasi basis data biasa (non-managed), sebelum tahap pendefinisian tabel tentu kita sudah menspesifikasikan kapasitas basis data tersebut: berapa besar penyimpanannya, berapa jumlah CPU-nya, berapa besar RAM-nya, dan lain-lain. Bagaimana kita melakukan ini pada DynamoDB?
Pada gambar pengaturan tabel di atas, bisa kita baca keterangan “Provisioned capacity set to 5 reads and 5 writes”. Inilah yang menjadi spesifikasi kapasitas tabel DynamoDB kita. Singkatnya, dengan 1 Read Capacity kita dapat membaca 1 item per detik dari tabel (ukuran item hingga 100 kB). Begitu juga dengan 1 Write Capacity kita dapat menulis 1 item per detik ke dalam tabel. Jika kita membaca atau menulis item lebih cepat atau lebih besar dari kapasitas yang kita setel, AWS akan mengirim error berupa ProvisionedThroughputExceededException. Tarif DynamoDB sendiri dihitung dari total Read Capacity dan Write Capacity di semua tabel yang kita miliki, ditambah total ukuran data tersimpan.
Hak Akses DynamoDB dari Fungsi Lambda
Selanjutnya, kita perlu membuka akses tulis DynamoDB dari fungsi Lambda yang kita gunakan untuk scraping. Caranya, buka halaman IAM (Identity and Access Management), lalu klik Roles. Di situ akan muncul lambda-role, yaitu role akses yang telah kita buat sebelumnya saat mendefinisikan fungsi Lambda.
Kita akan memasang policy baru pada role ini yang memungkinkan kita mengakses DynamoDB dari fungsi Lambda. Pada bagian Inline Policies, klik link “To create one, click here” lalu pilih Policy Generator. Di halaman berikutnya (Edit Permissions), pilih Allow pada field Effect, Amazon DynamoDB pada AWS Service, Put Item pada Actions, dan ARN tabel pada Amazon Resource Name (ARN). Klik Add Statement lalu klik Next Step. AWS akan men-generate kode policy berdasarkan pengaturan yang kita masukkan tadi. Klik Apply Policy untuk memasang policy ini pada fungsi Lambda.
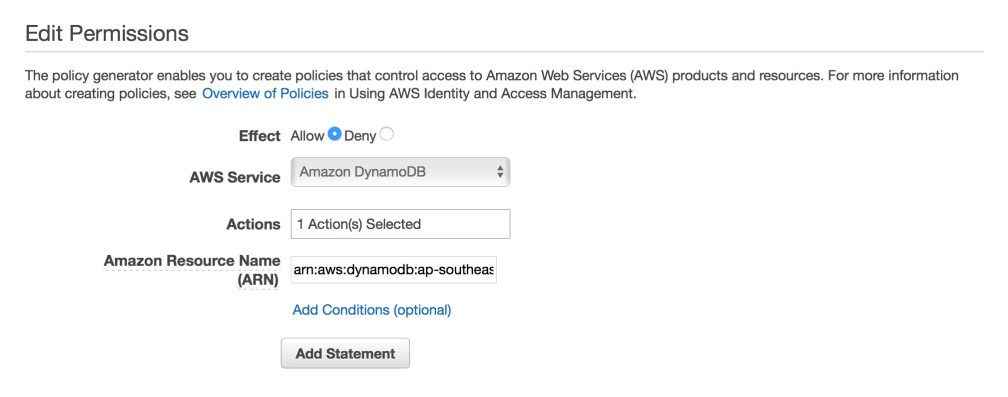
Pengaturan akses tulis DynamoDB
Scraping!
Fiuh, setelah (sedikit) capek menyetel DynamoDB, mari kita buat fungsi scraping CCTV Transjakarta di AWS Lambda. Kodenya begini:
| from datetime import datetime, timedelta | |
| import urllib2 | |
| from urllib2 import URLError | |
| import boto3 | |
| START_BYTE = b'\xff\xd8' | |
| END_BYTE = b'\xff\xd9' | |
| ITER_LIMIT = 10000 | |
| def capture_img(url): | |
| stream = urllib2.urlopen(url, timeout=15) | |
| all_bytes = '' | |
| i = 0 | |
| while True and (i < ITER_LIMIT): | |
| # Read MJPEG stream until start byte and end byte are found, or until ITER_LIMIT reads | |
| i += 1 | |
| all_bytes += stream.read(1024) | |
| a = all_bytes.find(START_BYTE) | |
| b = all_bytes.find(END_BYTE) | |
| if a != -1 and b != -1: | |
| return all_bytes[a : b+2] | |
| def write_to_dynamo(item): | |
| dynamodb = boto3.resource('dynamodb', region_name='ap-southeast-1') | |
| table = dynamodb.Table('cctv-jak') | |
| table.put_item(Item=item) | |
| def lambda_handler(event, context): | |
| loc_urls = { | |
| "Pondok Indah 1 N": "http://202.51.112.91:727/image2", | |
| "Pondok Indah 1 S": "http://202.51.112.91:728/image2", | |
| # other locations to scrape | |
| } | |
| records = {} | |
| for loc, url in loc_urls.iteritems(): | |
| try: | |
| img_byte_str = capture_img(url) | |
| if not img_byte_str: | |
| # Stream format not as expected, continue to next CCTV | |
| continue | |
| img_byte_str = img_byte_str.decode("ISO-8859-1") # for storage in DynamoDB | |
| # +7 hour: handle timezone difference from server time to WIB time | |
| timestamp = str(datetime.now() + timedelta(hours=7))[:19] | |
| records[loc] = { | |
| 'loc': loc, | |
| 'timestamp': timestamp, | |
| 'img_bytes': img_byte_str | |
| } | |
| write_to_dynamo(records[loc]) | |
| except URLError: | |
| # Skip on timeout error | |
| pass | |
| return records |
Klik Test untuk coba mengeksekusi fungsi, dan voila, Lambda akan men-scrape screenshot CCTV, menyimpannya di DynamoDB, dan mengembalikan hasil eksekusi.
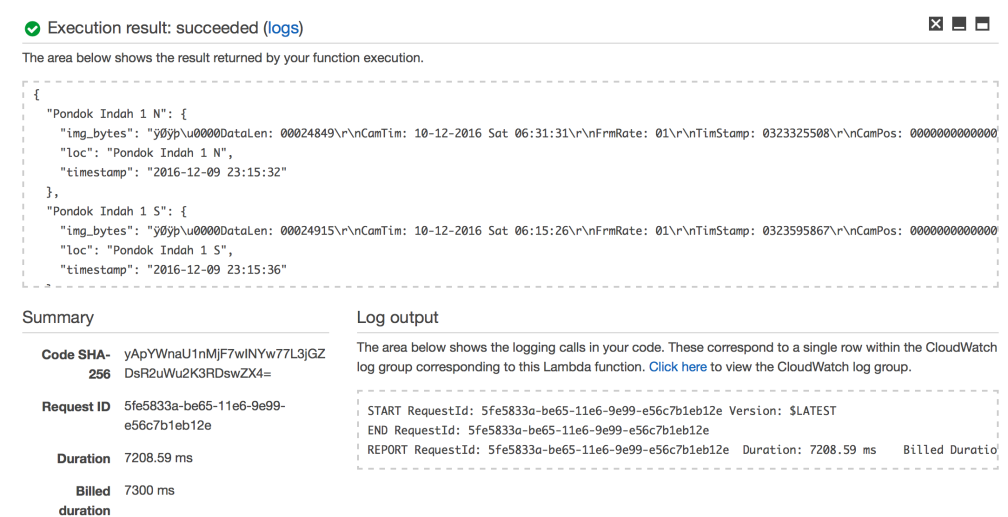
Hasil eksekusi fungsi Lambda untuk scraping CCTV Transjakarta
Menurut hasil di atas, untuk men-scrape 2 screenshot CCTV dibutuhkan waktu 7,3 detik, jadi jangan lupa menyesuaikan pengaturan timeout fungsi Lambda kalau mau men-scrape lebih banyak CCTV sekaligus. Sebagai informasi, saya menyetel timeout Lambda 2 menit dan 8 Write Capacity DynamoDB untuk men-scrape 8 CCTV.
Getting the data out
Terakhir, saat nanti data screenshot yang kita scrape sudah banyak, kita tentu mau mengunduh screenshot-screenshot tersebut. Kode untuk mengunduhnya lumayan panjang, dan karena pos ini juga sudah panjang, kodenya saya taruh di Gist saja ya.
Dalam 2 pos terakhir kita bereksplorasi men-scrape screenshot CCTV Transjakarta menggunakan AWS Lambda + Amazon DynamoDB. Seperti saya tulis di pos pertama, saya sudah mencoba cara ini, dan dengan biaya $0.15 saja saya bisa men-scrape plus mengunduh 37.000 screenshot CCTV (setara 1,5 GB).
Bagaimana dengan kamu? Sudah pernah pakai AWS Lambda atau Amazon DynamoDB? Untuk apa? Jangan lupa sharing ya di komentar!
