Setelah berbulan-bulan blog ini berkutat dengan regresi, sudah saatnya kita pindah topik. Beberapa waktu lalu saya sempat diminta seorang teman untuk menulis artikel tentang klasifikasi dalam pembelajaran mesin. Oke, kalau begitu mari kita bahas klasifikasi. Namun, sebelum menelaah algoritma klasifikasi satu per satu, mari kita bercerita terlebih dahulu tentang klasifikasi secara umum.
Apa Itu Klasifikasi?
Secara sangat sederhana, klasifikasi bisa diartikan sebagai proses menerka kategori (kelas). Kelas apa yang diterka? Bisa apa saja, misalnya menerka apakah seorang pengunjung Web e-commerce masih “ragu-ragu” dalam membeli sebuah produk atau tidak. Dari mana kita bisa menerka kelas tersebut? Sama halnya seperti regresi, kita menggunakan variabel-variabel (karakteristik) dari sebuah objek untuk melakukan klasifikasi terhadap objek tersebut. Untuk klasifikasi pengunjung Web e-commerce di atas, contoh variabel yang mungkin bisa digunakan misalnya berapa kali seorang pengunjung telah melihat laman produk dan berapa kali pengunjung tersebut telah bertransaksi selama 6 bulan terakhir. Dari hasil klasifikasi, kita sebagai pemilik Web e-commerce bisa melakukan aksi lebih lanjut, misalnya menawarkan potongan harga untuk pengunjung yang terklasifikasi sebagai “ragu-ragu”.
Model Klasifikasi
Model matematis untuk sebuah task klasifikasi bisa dinyatakan ke dalam persamaan:

di mana y menyatakan kelas dari poin data (objek) X, dan C adalah himpunan kelas yang terdefinisi dalam task klasifikasi tersebut. Misalnya, C = {Ragu-Ragu, Tidak} pada contoh di atas. Contoh fungsi f yang sangat sederhana adalah sebagai berikut:
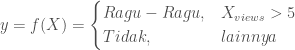
Persamaan di atas bisa dimaknakan: pengunjung diklasifikasikan sebagai Ragu-Ragu jika sudah melihat laman sebuah produk lebih dari lima kali.
Sama seperti regresi, tidak ada ketentuan khusus mengenai bentuk fungsi f, dan dua model klasifikasi yang berbeda bisa memiliki bentuk fungsi f yang berbeda ataupun sama. Perhatikan juga bahwa pada regresi, domain dari y (range dari fungsi f) adalah bilangan riil, sedangkan pada klasifikasi domain dari y adalah C. Inilah (satu-satunya?) aspek fundamental yang membedakan regresi dan klasifikasi dalam pembelajaran mesin.
Statistical Classification
Sebetulnya istilah klasifikasi yang kita pakai di atas perlu diperjelas lagi. Yang dimaksud dengan klasifikasi dalam pembelajaran mesin adalah klasifikasi berdasarkan data. Kita bisa saja mencoba menerka fungsi f tanpa berdasarkan data, alias secara manual. Sebagai contoh, perhatikan visualisasi dataset hipotetis untuk persoalan klasifikasi pengunjung e-commerce berikut.

Sangat mudah untuk mengklasifikasikan tipe pengunjung pada grafik di atas bukan? Pengunjung yang telah melihat sebuah produk lebih dari 5 kali dapat langsung kita klasifikasikan sebagai “Ragu-Ragu”. Namun, bagaimana jika datanya seperti grafik berikut:

Mungkin pembaca berpikir, “Ah, masih mudah juga kok mengklasifikasikan data di atas”. Sekarang, bagaimana jika ada lebih dari dua variabel, atau lebih dari dua kelas, atau lebih dari 1.000 poin data, atau tidak ada garis lurus yang bisa memisahkan poin data masing-masing kelas? You get the point. Menyusun fungsi f secara manual untuk mengklasifikasikan objek-objek dalam sebuah dataset bisa jadi sangat sulit atau bahkan mustahil dilakukan.
Di sinilah peran pembelajaran mesin, yang memungkinkan kita untuk dengan “otomatis” memperoleh fungsi f berdasarkan data yang kita miliki. Untuk lebih jelasnya mengenai pembuatan model dalam pembelajaran mesin, pembaca bisa lihat kembali artikel ini bagian Membuat Model Regresi.
Selanjutnya kita akan bercerita tentang algoritma k-NN untuk klasifikasi. Tunggu ya!
