Anda diundang ke sebuah pertemuan. Namun, Anda tidak tahu tema dari pertemuan tersebut, maupun kegiatan apa saja yang akan dilakukan di pertemuan tersebut. Anda benar-benar tidak tahu apakah pertemuan itu akan bermanfaat atau tidak untuk Anda. Yang Anda tahu, beberapa orang teman Anda juga diundang ke acara yang sama. Dalam kondisi seperti itu, apa yang Anda lakukan?
Cara yang biasanya dilakukan oleh banyak orang dalam menangani masalah seperti itu adalah dengan bertanya kepada teman-teman apakah mereka akan datang ke pertemuan tersebut atau tidak. Biasanya, orang-orang yang pertama ditanya adalah orang-orang yang dekat dengan Anda. Maka, Anda mencoba mengontak enam orang teman yang biasa jadi teman main Anda. Dari enam orang tersebut, empat orang menyatakan akan datang, tapi dua orang ternyata memutuskan tidak datang, entah mengapa alasannya. Kalau sudah seperti itu, keputusan apa yang Anda akan ambil?
Kemungkinan, Anda akan memutuskan untuk datang pada pertemuan itu, karena toh teman Anda banyak yang akan datang juga. Namun, apa yang terjadi jika dari tiga orang teman yang Anda tanya pertama kali (asumsikan mereka teman terdekat Anda dari enam orang tersebut), dua orang memutuskan tidak datang dan satu orang memutuskan untuk datang? Bila hanya tiga orang tersebut yang Anda tanya, apakah Anda akan tetap datang?
Bertanya pada Tetangga
Kasus di atas menggambarkan ide dari algoritma k-Nearest Neighbours (kNN). Anda ingin mengambil sebuah keputusan (kelas) antara datang atau tidak datang ke sebuah pertemuan. Untuk mendukung pengambilan keputusan tersebut, Anda melihat mayoritas dari keputusan teman-teman Anda (instance lainnya). Teman-teman tersebut Anda pilih berdasarkan kedekatannya dengan Anda. Ukuran kedekatan pertemanan ini bisa bermacam-macam: tetangga, satu hobi, satu kelas, atau hal-hal lainnya. Ukuran-ukuran tersebut bisa juga digunakan bersamaan, misalnya si A itu tetangga, satu hobi, dan satu kelas; sedangkan si B hanya satu kelas saja.
Asumsikan bahwa Anda sebegitu kolotnya(?) sehingga Anda bertanya dengan menyambangi satu per satu rumah teman Anda (yang kebetulan masih bertetangga dengan Anda). Jika digambarkan dalam diagram, maka kurang lebih bisa terlihat seperti di bawah ini.

Gambar 1: k-Nearest Neighbour
Diagram tersebut merupakan peta lokasi tempat tinggal Anda dan teman-teman Anda. Dari gambar tersebut, Anda adalah bintang merah di tengah — yang belum mempunyai kelas, bundaran berwarna ungu adalah teman yang memutuskan tidak datang, dan bundaran berwarna kuning adalah teman yang memutuskan untuk datang ke pertemuan tersebut. Nilai 
Representasi Matematis
Dalam cerita di atas, kelas yang dianggap sebagai mayoritas adalah kelas yang jumlah instance-nya setengahnya atau lebih dari

Formula itu dibaca: probabilitas kelas 
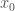
Yang jadi pertanyaan berikutnya biasanya adalah, “Berapakah nilai
Menentukan Nilai k
Masalah penyesuaian parameter ini memang selalu menjadi permasalahan bagi kebanyakan algoritma pembelajaran mesin. Penentuan nilai
 Gambar 2: Pengaruh nilai k terhadap pembatas keputusan | sumber: [1]
Gambar 2: Pengaruh nilai k terhadap pembatas keputusan | sumber: [1]
Dengan nilai 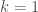

![Galat data latih vs data uji | sumber: [2]](https://tentangdata.files.wordpress.com/2015/08/screenshot-from-2015-08-29-142232.png)
Gambar 3: Galat data latih vs data uji | sumber: [2]
mengecil, i.e.classifier semakin fleksibel), maka error rate data latihnya semakin mengecil, tetapi error rate data ujinya tidak mencapai titik minimumnya. Walakin, semakin kaku classifier-nya, i.e. semakin besar nilai , tidak serta-merta berarti bahwa error rate data ujinya secara konstan mengecil.
Penjelasan di atas nyatanya tidak menjawab pertanyaan sebelumnya secara utuh, karena pada akhirnya ini menjadi sangat bergantung kepada kasus yang dihadapi. Lalu, apa makna bias dan variansi yang telah disebut di atas? Bagaimana pula cara mengukur “jarak” antarvariabel? Nah, untuk penjelasan lebih lanjutnya akan dibahas di pos-pos berikutnya ya!
Referensi:
[1] DeWilde, Burton. “Classification of Hand-written Digits (3).” Burton DeWilde. 26 Oktober 2012. Web. 28 Agustus 2015.
[2] James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning (p. 39-42). New York: Springer.
